KubeCon Europe 2026:OpenTelemetry 分布式追踪中的回溯采样 —— 减少 60% 尾部采样成本
Hi!欢迎来到 VictoriaMetrics 在 KubeCon Europe 2026 会场的分享议题 Retroactive Sampling with OpenTelemetry: Cut 90% Distributed Tracing Bandwidth Usage 实录!希望你会对以下成果感兴趣,并且在接下来的 10 分钟里了解它:
- “对比 OpenTelemetry 中的尾部采样,该方案可以把 Outbound 流量、数据采集链路的 CPU 和内存同时削减 60-70%。”
回溯采样与其他方案的对比 —— 详情见第 3 节
1. 背景
我们还是从人尽皆知的基础概念开始,不过如果你已经很熟悉 —— 请直接跳到第 2 节,你不会因此错过任何内容。
1.1 分布式追踪
Trace
这是分布式追踪,它的概念很简单:你有一套分布式系统、数十个微服务,在一个请求的处理过程中,它们相互调用。现在,每个微服务都把“它做了什么”绘制成 Spans,这些 Spans 按照时间、调用关系串联成一个 Trace。
Traces 数据使用是有成本的,一个 Trace 可以包含几百甚至上千个 Spans,每个 Span 中的数据少则数百 Bytes,多则上 KB。这意味着如果你的入口网关接收到了百万级的请求,那你的服务将轻轻松松产生 GB/s 的 Traces 数据。紧接着,采集、传输和处理这些数据就会考验你的带宽、CPU、内存和磁盘。
1.2 采样
常见的减少 Traces 数据量的方法是采样(Sampling),按采样发生的时机可以分为头部采样、尾部采样。
头部采样是指入口服务(例如网关)收到请求时立刻决定是否对它采样,并且把决策结果传播给这个调用链路中的其他服务,其他服务会遵从这个决策,保留或丢弃相关的 Spans。头部采样通常是随机的,它不会因为 Trace 中有用户感兴趣的情况,或者产生了异常而更改采样结果,只是暴力地丢弃数据。
尾部采样相对来说更贴合用户需求:Span 数据由服务产生,传输并暂存到中心化的 Collector,Collector 在稍等一段时间后,认为 Trace 已经结束,数据已经收集齐全,然后开始对其进行分析和采样,并将被采样的数据传输到下一个节点(例如 Traces 存储)。
尾部采样的亮点是根据实际 Trace 情况来决定是否采样,因为它可以观察到完整的 Trace 信息,这在头部采样中难以实现。
1.3 尾部采样的内存、计算与带宽
尾部采样的最大问题:它有成本,甚至可能比全额采集数据的成本还要昂贵。
首先,尾部采样把 Spans 按 Trace ID 聚合,暂存在内存中。若想将数据暂存足够长的时间,执行尾部采样的 Collector 就需要分配更多的内存资源。尽管有很多取巧的方案可以提前释放这些内存,例如在接收到 Root Span 时就进行采样决策,但是考虑到分布式系统中数据传输的延迟与不可靠性,没有任何方案可以保证所有 Span 在特定事件或者特定时间内抵达。因此,延长暂存时间窗口并在有限的内存中暂存更多的数据常常是用户更期望的。
其次,尾部采样所需要的资源远不止于 Collector 内存。
在生产环境中,大量的服务在产生数据,而这些数据必然不可能被单个 Collector 处理 —— 垂直扩容是有上限的,用户通常会部署数个 Collector 节点。但是基于尾部采样的特点,单个 Trace 中的 Spans 必须交给同一个 Collector 来处理,这意味着数据必须依照 Trace ID 进行路由,通常的做法是在 Collector 前部署 Load Balancer:既可单独部署一层 Load Balancer,也可以在每个 Node 上部署数据采集 Agent,由这些 Agent 兼任 Load Balancer。
但是不管怎样,这些额外的路由和计算都必不可少。
最后,网络成本。在这些部署方案中,Traces 数据都需要从一个 Node 转发到另一个 Node 上,这需要占用每个 Node 的带宽。运气好的话,你的部署规模足够小且合理,那这些 Node 之间的带宽和流量可能是免费、无需担心的。然而,一旦你需要在跨集群、跨可区甚至多个云服务商之间实施复杂的分布式追踪,你就没办法忽略带宽的成本:
- 出口带宽是有限的。
- 出口流量是收费的。
但是这些传输的数据真的有被用上吗?很多时候,最终被保留的数据只有不到 10%,在超大规模下,这个数字经常会降低到 1%、0.1%。
这意味着你为 100% 的 Traces 数据支付了内存、计算(CPU)和网络成本,而其中绝大部分数据只会存活数十秒,然后被扔进垃圾桶。
2. 回溯采样
回溯采样的核心思路正是通过减少不必要的数据传输,来减少:
- 内存中需要缓存的数据;
- 传输和路由数据所需的 CPU;
- 传输数据所需的网络带宽。
2.1 发送与回溯数据
如果你仔细观察一个 Span 所包含的 Attributes,并对比你正在使用的尾部采样策略,你会发现其中大部分 Attributes 都和采样决策无关。
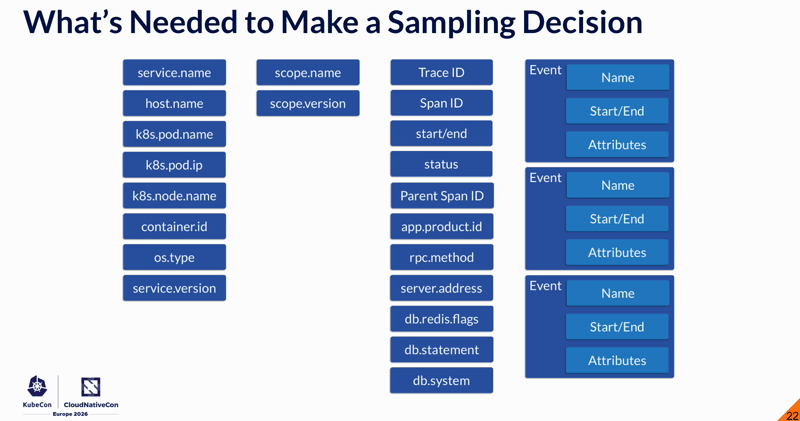
关键 Attributes
例如,若用户希望通过尾部采样保留:
- 包含错误的 Traces;
- 耗时超长(5s)的 Traces;
- 1% 其余(健康的)Traces。
在决策时,诸如 os.version、sdk.version、request.path、cmd 这些包含大量文本的 Attributes 几乎没有任何价值。Collector 仅需要 trace_id、每个 Span 的 start_time 及 end_time,还有 status_code 即可完成决策。
改进尾部采样的思路可以是:每个 Node 的 Agent 暂存 Trace Spans,同时提取关键 Attributes 发送给 Collector;Collector 进行决策,随后传播决策到 Agent 上;Agent 结合决策结果原地丢弃部分 Spans,并将被采样的 Spans 直接发送到 Traces 存储。
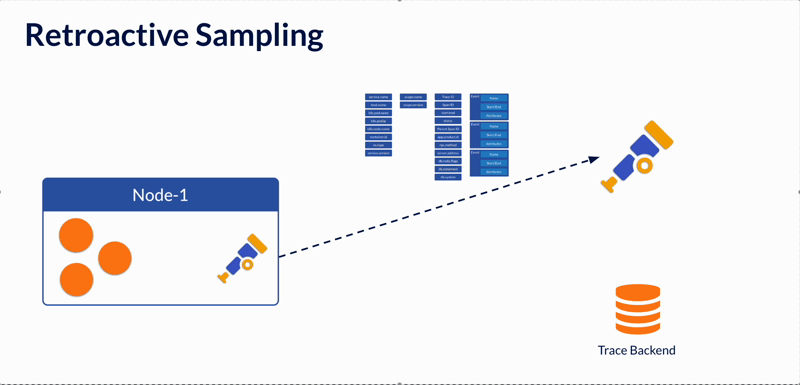
回溯采样
首先,在 Agent 中用如下数据结构来替代经典尾部采样传输的完整 Span:
+---------------------------+-----------------+-----------------+-----------------+
| 16 bytes | 8 bytes | 8 bytes | 1 byte |
+---------------------------+-----------------+-----------------+-----------------+
| trace_id | start_time | end_time | status_code |
+---------------------------+-----------------+-----------------+-----------------+
在 Collector 中,我们使用 2 个 Hashmap 作为内存缓冲区,按照 trace_id 聚合数据:
+------------+ +----------------+----------------+---------------+
| trace_id | ---> | start_time | end_time | status_code |
cur ---> +------------+ +----------------+----------------+---------------+
| trace_id | ---> | start_time | end_time | status_code |
+------------+ +----------------+----------------+---------------+
+------------+ +----------------+----------------+---------------+
| trace_id | ---> | start_time | end_time | status_code |
prev --> +------------+ +----------------+----------------+---------------+
| trace_id | ---> | start_time | end_time | status_code |
+------------+ +----------------+----------------+---------------+
使用两个 Hashmap(cur 与 prev)进行轮转是经典的双缓冲设计思路:
cur可以接收新的trace_id,并且 Attributes 也可以被更新;- 在 30 秒后,
cur将轮转成prev,prev不再接受新的trace_id,但是已存在的内容可以被更新; - 再过 30 秒后,对
prev进行采样决策。
这可以保证每个 prev 中的 trace_id 都至少存活了 30 秒时间长度,可持续被查找和更新,并且实现简单。
在采样决策后,Collector 需要将被采样的 trace_id 发送回各个 Agent,其实现可以是 Push-base 也可以是 Pull-base;可以是无差别 Fanout 所有 trace_id,也可以使用额外内存空间记录每个 Agent 发送过来的 trace_id,并只返回所需的 trace_id。
2.2 原始数据的暂存优化
在回溯采样中,一个关键实现是:原本由尾部采样 Collector 缓存的完整 Span 需要改由 Agent 进行缓存,并仅在必须时取用。若使用与尾部采样使用的内存型数据结构,就意味着回溯采样仅仅是将内存压力由处于中央的 Collector 转移到了边缘的 Agent,而没有减少实际需要的空间。
因此,我们考虑用磁盘来替代内存,以减轻 Agent 的内存开销。而在磁盘上读写数据,最高效的无疑是 FIFO 队列,理想情况下它可以将所需的随机 I/O 次数降到极低。
在我们的 Prototype 实现中,Traces 数据会被这样处理:
- 每批 Trace Spans 会被 Marshal 成二进制数据,携带当前时间戳作为一个 Block,写入磁盘 FIFO 队列;
- 此时另一条路径也在同步执行:提取关键数据送往 Collector 进行采样。
- Worker 会消费这个 FIFO 队列。在消费到一个 Block 时,检查时间戳来判断这批 Spans 在 FIFO 队列存活了多久;
- 确认或等待这批 Spans 存活超过指定时长(如 1 分钟)后,结合(已经收到的)采样结果,丢弃其中部分 Spans,并将被采样的 Spans 发送至 Traces 后端。
因此,Agent 的简要流程可以用下图表示:
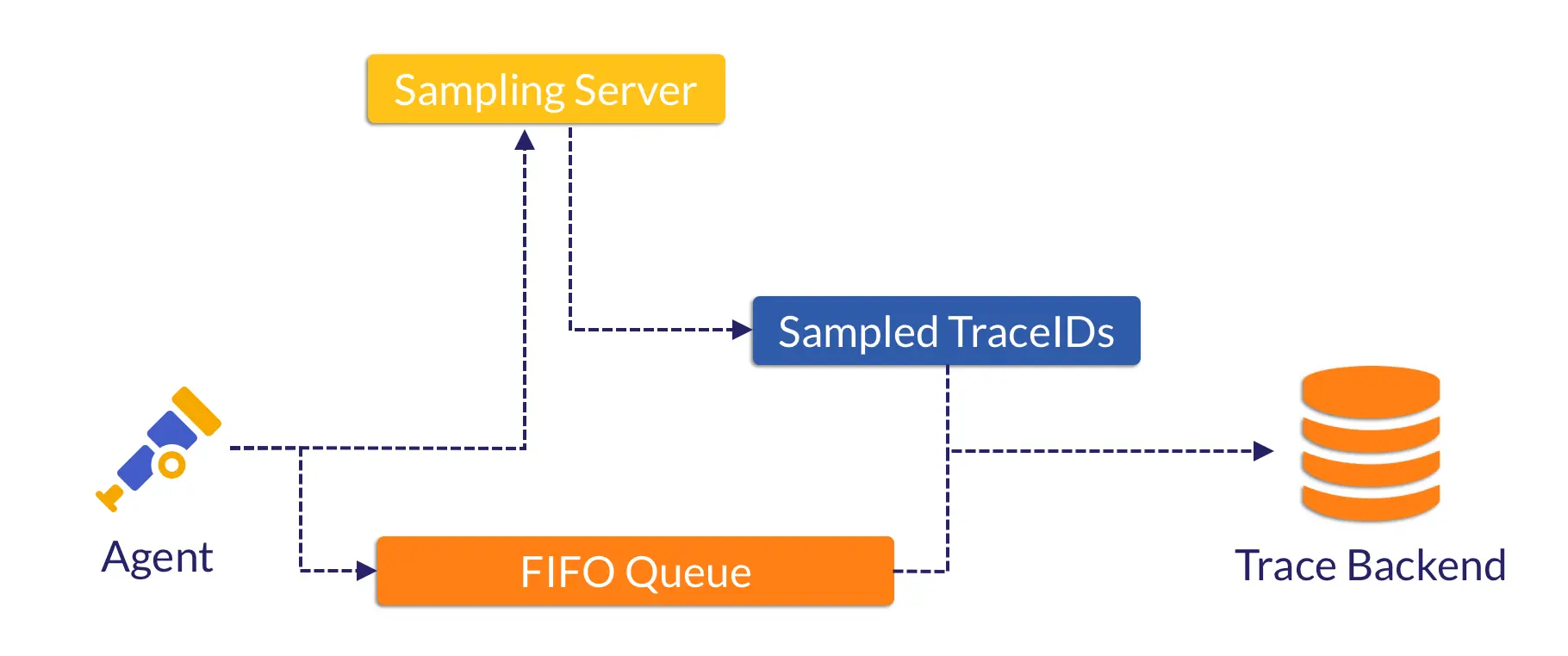
回溯采样 Agent
3. Benchmark 对比
枯燥的理论到此暂告一段落,我们用 OpenTelemetry Demo 结合流量回放做了一些测试,以检验这个思路是否真的可行。
在测试中,我们想对比:无采样、尾部采样和回溯采样,因此我们部署了:
- App(Load Generator)、OpenTelemetry Agent 和 VictoriaTraces,分别负责生成数据、转发来自同 Node 的数据、存储数据;
- 作为对照,在尾部采样方案中额外部署了 OpenTelemetry Collector 在 Agent 和 VictoriaTraces 之间;
- 作为对照,在回溯采样方案中额外部署了 Sampling Server,同样在 Agent 和 VictoriaTraces 之间。此外,OpenTelemetry Agent 实现了回溯采样所需的 Processor,负责缓冲、提取关键数据等操作。
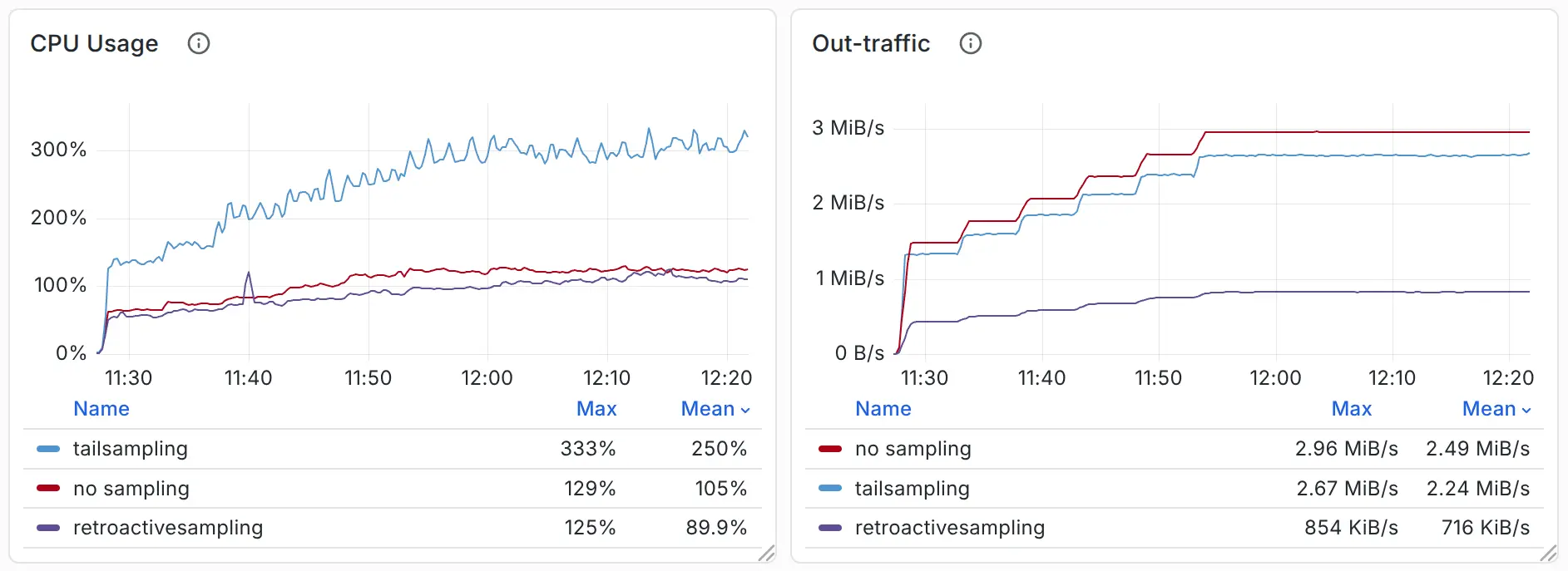
通过 Load Generator 产生 15k-30k Spans/s 的压力,我们可以观察到三者的 CPU、内存、Outbound 流量对比如下:
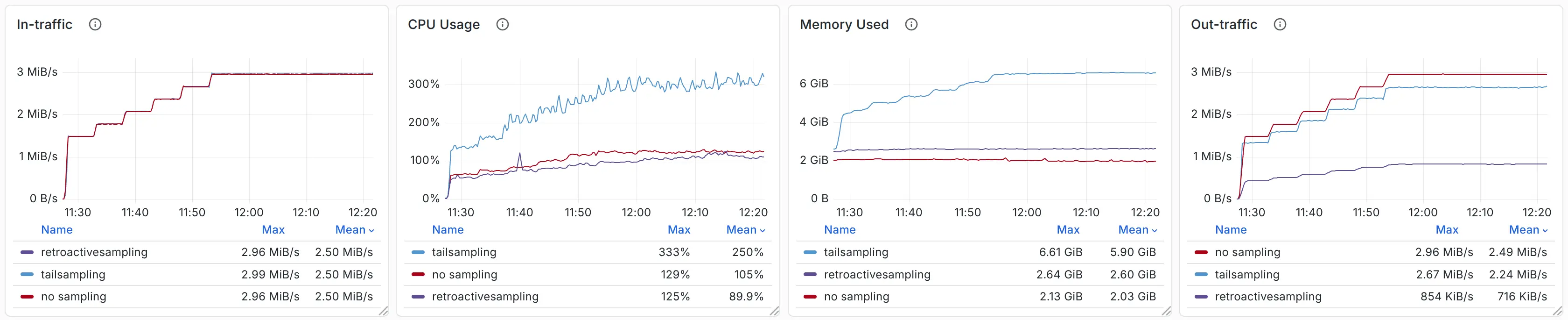
Comparison
另外,作为参考,回溯采样中所使用的总磁盘空间如下。粗略计算可知,每个节点所需的读写速度要求并不高,因此缓冲区的介质不应成为实施回溯采样的瓶颈,也侧面说明 OpenTelemetry 尾部采样所使用的内存缓冲区仍有可优化空间。
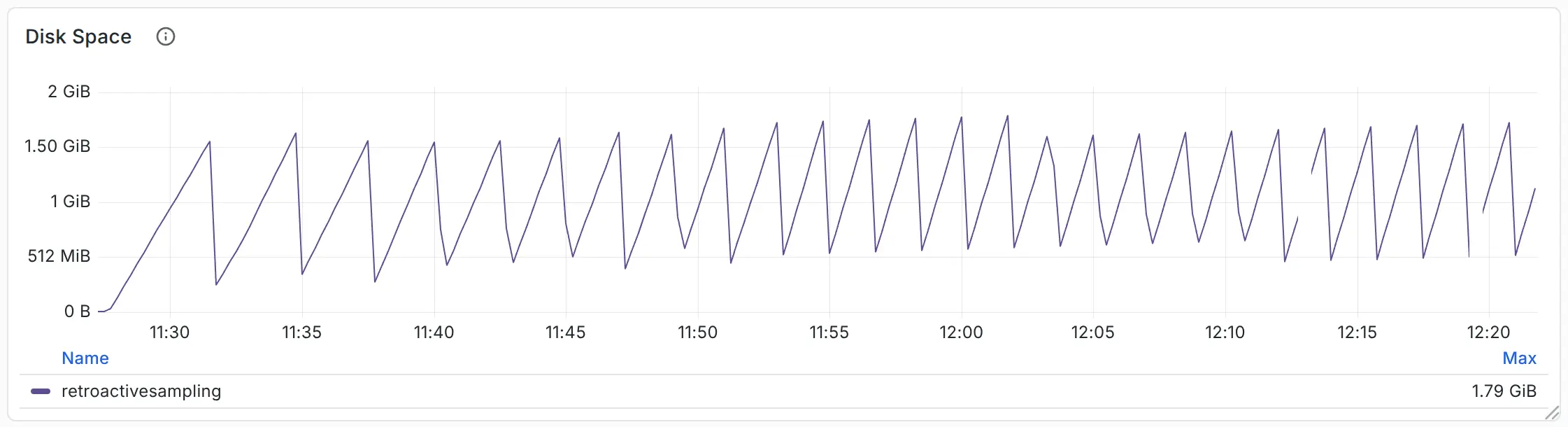
磁盘用量
4. 讨论
每种采样方案都理应有其长处和短处,回溯采样也不例外,它不是银弹。最容易被质疑的问题:回溯采样提供给 Collector 的采样决策依据太少了,如果用户想根据 10 个 Attributes 采样怎么办?
由于回溯采样的核心思想在于减少不必要的数据离开本地节点,如果采样涉及的数据太多(最极端的情况:每个 Attributes 都需要使用到),那回溯采样似乎就失去了它的价值。
不过我们还是可以从暴力的解决方案:如果所需要的 Attributes 不算多,那直接扩展采样使用的数据结构即可 —— 尽管这会占用更多带宽和内存缓冲空间,但是相比传输完整的 Span,这仍然是“较为节约”的:
+-------------+---------------+-------------+---------------+---------------+----------------+
| 16 bytes | 8 bytes | 8 bytes | 1 byte | 8 bytes | 64 bytes |
+-------------+---------------+-------------+---------------+---------------+----------------+
| trace_id | start_time | end_time | status_code | app_version | endpoint |
+-------------+---------------+-------------+---------------+---------------+----------------+
除此之外,还有其他方案吗?
4.1 变体:本地+远程采样
如果我们再深入思考一下:采样决策需要关键 Attributes,但是并不是所有关键 Attributes 都需要发送给 Collector。这是更进阶的回溯采样思路。
所谓的“关键 Attributes”实际上可以继续细分为 2 类:
- 需要先聚合才能作出采样判断,如 Span 的
start_time、end_time需要经过聚合后才能计算出 Trace 的耗时; - 无需聚合就能作出采样判断,如根据
status_code、app_version可以直接判断一个 Trace 是否因满足“包含错误”或者“指定版本”而被采样。
针对 1 类 Attributes,需要遵循经典的回溯采样要求,发送给 Collector 处理;针对 2 类的 Attributes,Agent 足以作出决策,剩下的只是将这个决策(trace_id)传播给其他 Agent,让它们将相关 Spans 也发送给 Traces 后端。
在上一小节中所提出的问题,“根据 10 个 Attributes 采样”,并不代表 10 个 Attributes 都需要被聚合和计算。若这些 Attributes 及对应的采样条件都只是 Boolean 的判断,那么当 Span 经过 Agent 时,Agent 就可以检查这 10 个 Attributes 然后决定是否要采样:
- 如果需要采样,Agent 应该将
trace_id发送给 Collector,由 Collector 进行广播; - 如果不需要采样,Agent 应该将
start_time、end_time等数据发给 Collector,由 Collector 进行计算和判断。
如此一来,Agent 实际上需要发送的数据可以抽象成下面的格式,并且也无需因判定条件改变而塞入所有相关 Attributes:
+-------------+-------------------+-------------------------+-------------------------+
| 1 byte | 16 bytes | 8 bytes | 8 bytes |
+-------------+-------------------+-------------------------+-------------------------+
| sampled | trace_id | start_time (opt) | end_time (opt) |
+-------------+-------------------+-------------------------+-------------------------+
4.2 平替:基于磁盘的尾部采样
我们在前面提到,回溯采样节约的内存空间很大程度是因为在 Agent 中使用磁盘代替了内存,这个思路同样可以实现在尾部采样中。
目前,OpenTelemetry 社区已经有将尾部采样的内存数据下放至磁盘的提议 #42326,具体磁盘存储使用的是 Pebble,一个 Go 语言实现的 Key-value 数据库。
![#42326 [processor/tailsampling] Offloading trace storage to disk for scalability](https://jiekun.dev/posts/202603-kubecon-eu-2026/disk_based_tailsampling.webp)
#42326 [processor/tailsampling] Offloading trace storage to disk for scalability
目前的进展,在 Benchmark 中,该方案比原始的尾部采样实现减少了超过 80% 的内存,但是增加了 4x CPU 使用率。
| Metric | In-Memory | Pebble (Disk) | Relative |
|---|---|---|---|
| Peak memory (MB) | 3420.63 | 638.78 | -81.32% (0.19x) |
| Avg memory (MB) | 2646.63 | 471.15 | -82.20% (0.18x) |
| Avg CPU (%) | 12.88 | 96.59 | +649.92% (7.50x) |
| Peak CPU (%) | 42.14 | 230.67 | +447.39% (5.47x) |
考虑到这不是最终的实现,这些数字可能还会持续更新,我们也希望在未来能将它们加入与回溯采样的对比中。
不过目前,我们还是可以从数据结构的角度比较一下。使用 Pebble,也就是使用 Key-value 存储,通常意味着数据应该按照 Key 进行排序,以加速对 Key 的查询 —— 这非常符合场景:为了实施尾部采样,需要按照 trace_id 来查找相关 Spans。然而,这些 Span 是在不同的时间抵达 Collector 的,想要将相关的 Span 都排列在一起,意味着需要经常调整数据的位置:
- 如果使用的是类 B+ Tree 的数据结构,那么插入数据时可能需要旋转叶子节点。这是针对查询优化的数据结构,因此耗时操作发生在数据写入时。
- 如果使用的是类 LSM Tree 的数据结构,那么重排列发生在 Compaction 过程。这是针对写入优化的数据结构,因此数据仅在每层有序排列,而数据的查询需要扫描多层数据。
不管怎样,这似乎都存在一些额外的计算和 I/O 操作,这可能是当前 Pebble 实现中 CPU 不降反升的原因(之一)。当然,也可能仅仅是未进行相关优化,我们暂不得而知。
如果你还记得,我们解释过“为什么回溯采样使用 FIFO 队列” —— 消灭随机 I/O,这对所有磁盘数据结构的设计至关重要。我们的想法是:分离查询与简单读写。随机查找应该使用内存型数据结构,这是它最擅长的,并且在回溯采样中也能被很好地执行(因为所有路径的数据体积都得到控制,不需要太多的内存空间)。而对于磁盘上的数据,如果能设计成只需要顺序的读写,那就再好不过了。
5. 总结
通过在 KubeCon + CloudNativeCon 上的演讲以及这篇博客,我们希望传播回溯采样的思路,而不止于具体实现。
当然,谈到实现,在我们的 Benchmark 中回溯采样还只是个 Prototype,我们既希望能将具体实现贡献给 OpenTelemetry 因此更多用户可以受益,也希望 VictoriaTraces 自家的 Agent(vtagent)可以具备一样的功能,具体应该在 2026 下半年随新版本一起发布 —— 100% 开源。
但是,回溯采样的核心在于思路而非实现,用户只需要从数据传输入手:减少不必要的数据传输就可以同时优化带宽、CPU 和内存。
同时,更多考虑基于磁盘的方案,并且避免不必要的查询或者随机 I/O。我们见过许多借助 Kafka 等消息队列的延迟采样方案,它们也或多或少与回溯采样有一些交集。在实现上复用企业内良好维护的基础设施,而不引入新的轮子,同样是很好的选择。
6. 延伸阅读
回溯采样的思路出自于 NSDI 2023 论文 The Benefit of Hindsight: Tracing Edge-Cases in Distributed Systems,作者 Lei Zhang。尽管实现上与 VictoriaMetrics 的 Prototype 不同,但论文阐述了大量的细节以及可能的 Trade-off,我们十分建议感兴趣的工程师阅读了解原始的设计。