Elasticsearch倒排索引原理 数据写入与查询过程
Elasticsearch在生产中充当的角色
业务上,最早启用Elasticsearch(下称ES)是为了解决模糊查询的问题。具体业务场景为大量抓取回来的短视频内容、热门微博、公众号文章、小红书笔记、信息流新闻文章等,需要支持用户模糊查找,而随着每日新增的内容越来越多,这些信息已经积累到单个媒体数千万近亿的数量,因此依靠MySQL的模糊查询是无法满足性能上的要求,考虑引入对应的搜索引擎来解决,于是就将数据的特定字段迁移至ES以支持快速高效的模糊查询,并将查询得到的ID取回MySQL匹配再将详细内容返回。
Elasticsearch为什么能够支持高效的模糊查询
倒排索引原理
为了支持模糊查询,用户输入关键词之后,需要快速定位到这些词对应的词条,思路与MySQL的LIKE一样,但是MySQL没有实现对应的方案以支持快速定位。ES在这块上略有不同,利用倒排索引(Inverted Index)可以直接获取到文档的ID。下面来简单介绍一下倒排索引的结构。
为了便于理解,介绍的实现与具体实现会有不一致。
现在有以下的数据行:
| id | 书名 | 出版社 |
|---|---|---|
| 1 | 高性能MySQL | 电子工业出版社 |
| 2 | Elasticsearch服务器开发 | 人民邮电出版社 |
| 3 | 深入理解Elasticsearch | 机械工业出版社 |
在写入数据,也就是索引(动词)的过程中:
(1)ES首先会将数据进行分析,如”高性能MySQL”拆分成“高性能”和“MySQL”等词条(tokens),同理,“电子工业出版社”可以被拆分成“电子”、“工业”、“出版社”;
(2) 拆分完毕后添加至对应的倒排索引中:
| 词条 | 对应id |
|---|---|
| 高性能 | 1 |
| MySQL | 1 |
| 电子 | 1 |
| 工业 | 1 |
| 出版社 | 1 |
(3)这样当Client查询“工业”一词的时候,就可以快速定位到id为1的数据行;
(4)同理对id为2和3的数据分析和索引之后,倒排索引变成:
| 词条 | 对应id |
|---|---|
| 高性能 | 1 |
| MySQL | 1 |
| 电子 | 1 |
| 工业 | 1, 3 |
| 出版社 | 1, 2, 3 |
| Elasticsearch | 2, 3 |
| 服务器 | 2 |
| 开发 | 2 |
| 人民 | 2 |
| 邮电 | 2 |
| 深入 | 3 |
| 理解 | 3 |
(5)举例搜索“工业”一词的时候,就应该定位到id为1和2的行
附上官方文档中的倒排索引势力,格式略有不同但是原理是相近的
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------
倒排索引和分析的具体实现
倒排索引具体实现在官网文档中粗略查询了一下没有具体介绍,估计被埋在了厚厚的文档堆中。根据其他资料显示,倒排索引实现方法多种,主要如BSBI和SPIMI等,参考博客《倒排索引构建算法BSBI和SPIMI》。
在具体的分析过程中,Elasticsearch会使用多种分析器将文本拆分成用于搜索的词条,然后将这些词条统一化以提高“可搜索性”。具体来讲,分析器应该包含如下功能:
(1)字符过滤器:如去除HTML,字符转换如&转为and
(2)分词器:如遇到空格和标点将文本拆分成词条
(3)Token过滤器:如将大小写统一,增加词条(如jump、leap等同义词)
ES内置有多种可选择的分析器,在业务中我们负责写入数据的同事使用的是针对中文分词的分词器以正确处理中文文本。
经过这些处理之后倒排索引生成,就能实现用于模糊查询的功能了。
Elasticsearch数据写入的过程
预备知识
在ES中,数据结构和MySQL相似但也略有不同,类比来看,ES的存储从上至下可以类比成:
索引(Index):相当于MySQL中的DB
文档类型(Doc Type):相当于MySQL的Table
文档(Doc):相当于MySQL中的一行数据
ES的索引并非可以理解为一整块数据块,由不同的doc构成doc type然后聚集在一起就是index。实际上ES的索引是由一个或多个分片组成的,每个分片包含了文档集的一部分。每个分片又可以又对应的副本。
因此,按照默认配置,ES的每个索引会切分出5个分片,而每个分片又有各自对应的副本,所以一共是10个分片。
分片,具体来说就是Lucene索引,因此可以看作ES的索引是由多个Lucene索引(分片)组成的,这些Lucene索引上包含了部分的doc。
继续细分Lucene索引,ES引入了按段搜索的概念,每个Lucene索引都是由多个段组成的,这些段具体而言就是,自身就是一个倒排索引。每个Lucene索引均包含了一个提交点(Commit Point)和多个段。
一下引入多种概念可能有点让人搞不懂,不要紧,下面借助一些官方的图例来理解一下。
数据如何写入
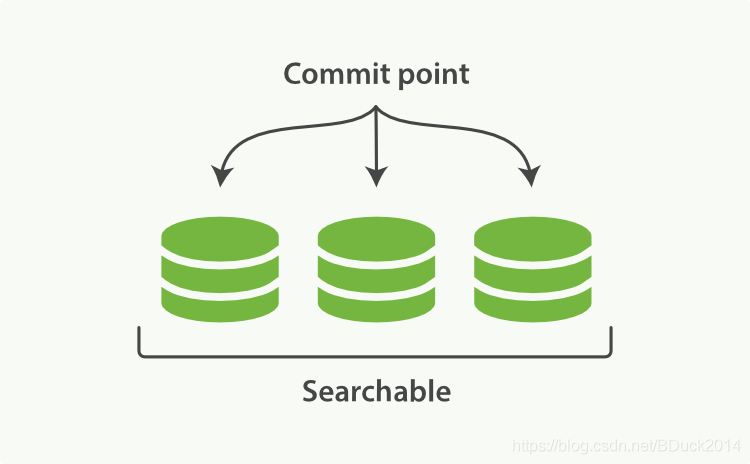
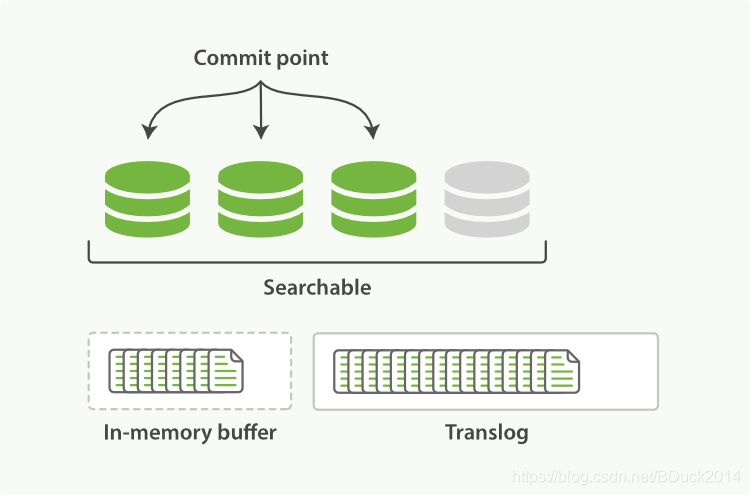
记住官方这张图,图中一个Lucene索引包含了3个段和一个提交点,当新增数据的时候:
(1)新的doc存放至内存缓冲区(In-memory indexing buffer)中,准备被提交(New documents are collected in an in-memory indexing buffer);
(2)缓冲区的内容提交(Every so often, the buffer is commited):
-
一个新的段被写至磁盘中
-
一个新的、包含新段名称的提交点被写至磁盘中
-
所有在文件系统缓存中的待写入的数据被写入(flush)至磁盘,磁盘同步完成
-
A new segment—a supplementary inverted index—is written to disk.
-
A new commit point is written to disk, which includes the name of the new segment.
-
The disk is fsync’ed—all writes waiting in the filesystem cache are flushed to disk, to ensure that they have been physically written.
由于有按段写入缓冲区、写入磁盘的过程存在,ES的新增数据的搜索并不是实时的——近实时搜索。
近实时搜索
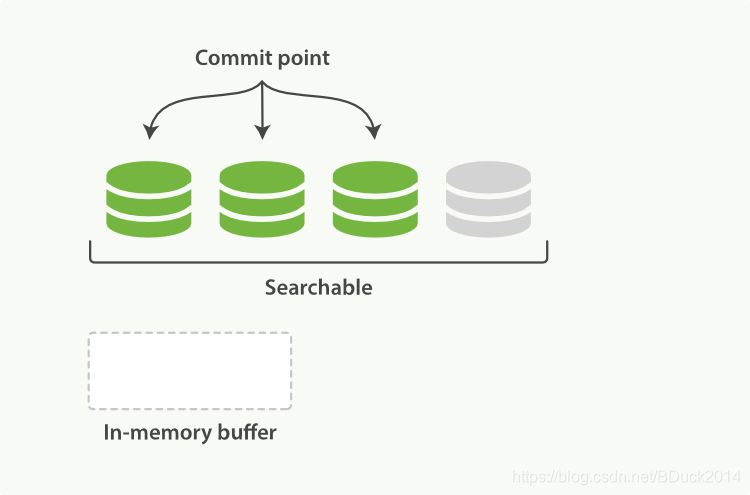
因为需要把对应的段写入之后才能够查询,因此新数据进来的瞬间是无法搜索到的,即使已经按段(意味着倒排索引已经建立好)存在内存中。
提交一个新的段至磁盘需要进行fsync的操作,这是个代价大的操作因此需要在内存缓冲区和磁盘之间增加新的缓冲区,使得在fsync操作之前文档就能够被搜索到。
在Elasticsearch和磁盘之间是文件系统缓存。下图表示段已经从内存缓冲区中同步至文件系统缓存(灰色段),借助缓存,此时文档已经可以被检索到,但是还没有被提交。这个从内存缓冲区至文件系统缓存的过程称为refresh,这是一个写入和打开新段的轻量过程。
我们可以在设置中设置refresh的间隔时间,也可以通过refresh api进行手动refresh使得新增的doc“实时”可见。
# 修改my_logs索引的refresh时间间隔
PUT /my_logs
{
"settings": {
"refresh_interval": "30s"
}
}
# 请求接口对blogs进行refresh操作
POST /blogs/_refresh
数据持久化
既然使用到了内存及文件系统缓存,那么必然有数据丢失的风险。尽管通过refresh实现了近实时搜索,但是还是要时常进行完整commit来确保能从失败中恢复出来。
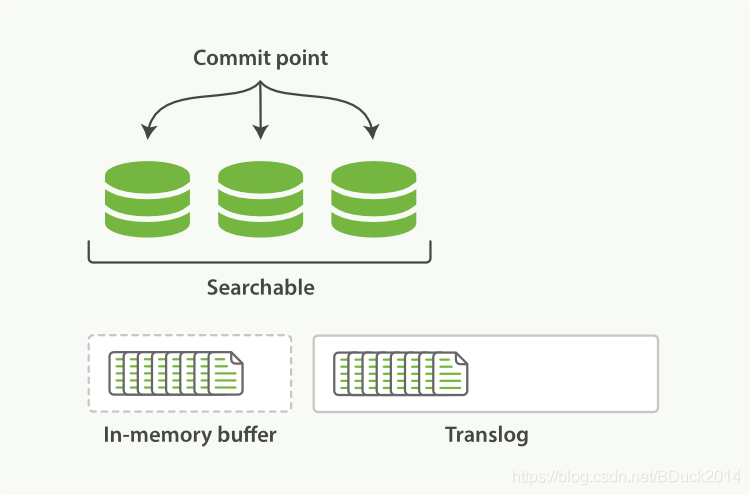
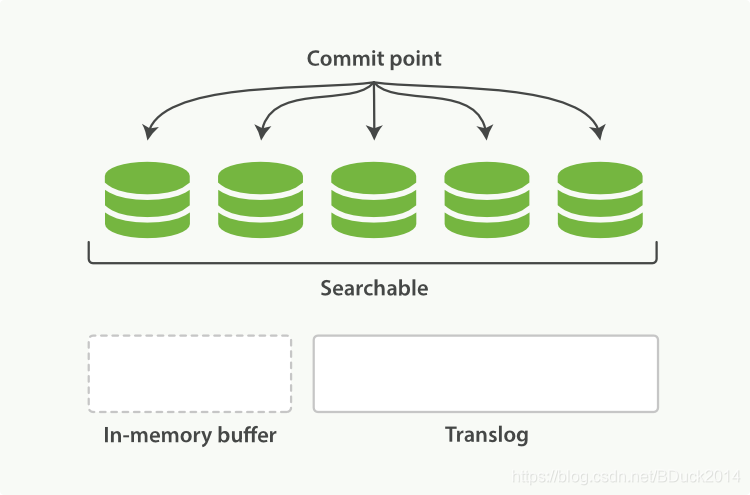
ES中使用了一个translog,在文档被索引(动词)后,就会被添加到内存缓冲区并且追加到translog:
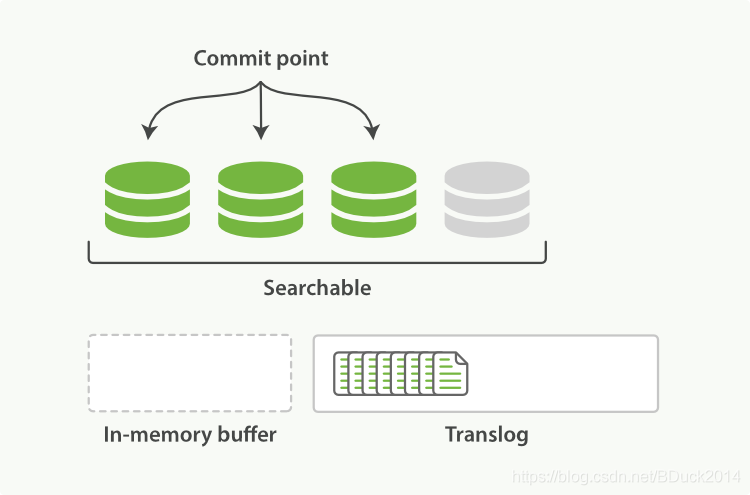
在refresh操作过后,In-memory buffer区域的段转移到文件缓冲区,也就是灰色段:
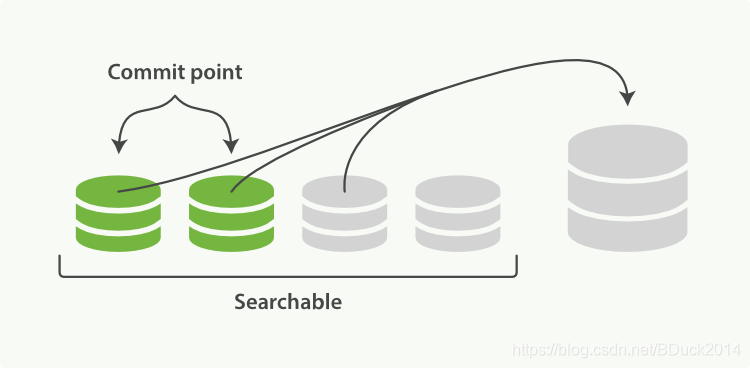
随着进程的继续,doc会逐渐积累:
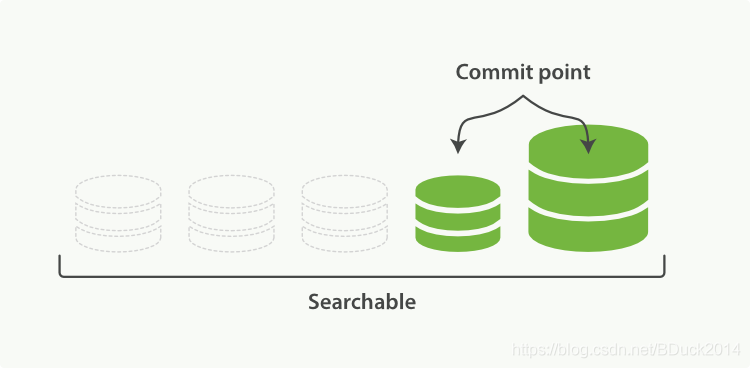
经过一定时间或者translog变大之后,这些translog就会通过fsync提交,现在看到所有的段都是绿色,意味着可搜索、持久化完成。文件缓存系统上的段(灰色)在fsync时会被清空(flush),旧的translog会被删除,创建新的空translog:
同样,flush操作也和refresh类似,有对应API可调用:
POST /blogs/_flush
这里引用官方文档对translog的安全性的描述:
Translog 有多安全?
translog 的目的是保证操作不会丢失。这引出了这个问题: Translog 有多安全 ?
在文件被 fsync 到磁盘前,被写入的文件在重启之后就会丢失。默认 translog 是每 5 秒被 fsync 刷新到硬盘, 或者在每次写请求完成之后执行(e.g. index, delete, update, bulk)。这个过程在主分片和复制分片都会发生。最终, 基本上,这意味着在整个请求被 fsync 到主分片和复制分片的translog之前,你的客户端不会得到一个 200 OK 响应。
在每次请求后都执行一个 fsync 会带来一些性能损失,尽管实践表明这种损失相对较小(特别是bulk导入,它在一次请求中平摊了大量文档的开销)。
但是对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync 还是比较有益的。比如,写入的数据被缓存到内存中,再每5秒执行一次 fsync 。
这个行为可以通过设置 durability 参数为 async 来启用:
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
这个选项可以针对索引单独设置,并且可以动态进行修改。如果你决定使用异步 translog 的话,你需要 保证 在发生crash时,丢失掉 sync_interval 时间段的数据也无所谓。请在决定前知晓这个特性。
如果你不确定这个行为的后果,最好是使用默认的参数( “index.translog.durability”: “request” )来避免数据丢失。
段合并
随着refresh的不断调用,ES中的段会越来越多,太多的段会消耗更多的资源,因为查询是要在各个段中进行检查的,会拖慢查询效率。
ES通过将小段合并至大段来解决这个积累的问题,这个动作是自动的:
(1) 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
(2)合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
合并之后老的段会被删除,fsync将新的段提交至磁盘
Elasticsearch数据查询的过程
上文已经提过,ES将索引分成不同的分片(Luence索引),再由不同分片中的段(倒排索引)存储具体的数据。为了获取对应的doc,ES需要查询所有分片并且对结果进行合并。
默认的索引过程
ES根据文档的标识符,选择文档应该进入的分片(当然这一步也支持手动指定分片)。默认情况下,通过计算文档的Hash值将文档分配到对应分片上。
取出过程
大多数情况下,为了得到想要的结果,需要查询所有的分片。
我们把请求发送到ES的一个节点,根据请求的搜索类型:
(1)ES首先查询所有节点获得对应符合的文档的标识符+得分(用于排序)
(2)节点根据这些所有的标识符和得分,判断需要取出的对应文档范围(如得分top5的文档),重新构建一个内部请求,再到对应分片上获取这些文档的具体内容。